The Trading Platform Maintenance Guide for Brokerage Leaders


When trading platform maintenance fails, the damage shows up in your P&L before it shows up in your server logs. Lost trades, degraded fills, and compliance findings all trace back to the same root cause: a maintenance posture where routine maintenance tasks were treated as engineering problems instead of a business discipline.
This guide covers maintenance from a business leadership perspective. You will learn which metrics to track, what to ask your internal teams and vendors, and how to recognize when a problem has outgrown your in-house capacity.
Key Takeaways
- Client churn and direct revenue loss are most often driven by unplanned platform downtime and execution degradation, both of which can be mitigated through preventive maintenance.
- Financial regulators demand documented audit trails, patch logs, and change management records rather than verbal assurances of system security.
- Tracking your ratio of scheduled to reactive maintenance within your maintenance schedule provides an accurate leading indicator of compounding technical debt before a major outage occurs.
- A complete maintenance strategy must simultaneously cover execution health, liquidity integrity, back-office continuity, and security to prevent cascading system failures.
Why Maintenance Is a Business Decision
Every maintenance gap has a price tag attached to it. An hour of unplanned downtime during the London-New York overlap can cost a mid-size broker tens of thousands in lost volume. A 2–3 basis point drift in average fill quality, barely noticeable in a single session, compounds into significant revenue loss across a month of high-volume flow.
Institutional clients track these numbers. They benchmark your execution quality over time and migrate their flow quietly when degradation becomes consistent.
Three risks run through every maintenance decision you make:
- Revenue risk. Downtime and latency spikes cost you trades. Fill degradation costs you clients. Both hit the P&L directly.
- Regulatory risk. Incomplete change management logs, broken audit trails, and late compliance reports create findings that turn into fines or license conditions. Regulators expect documented proof that your systems are actively maintained.
- Competitive risk. A platform that falls behind on updates loses access to routing improvements and new asset class support. Competitors who stay current widen their execution quality advantage quarter by quarter.
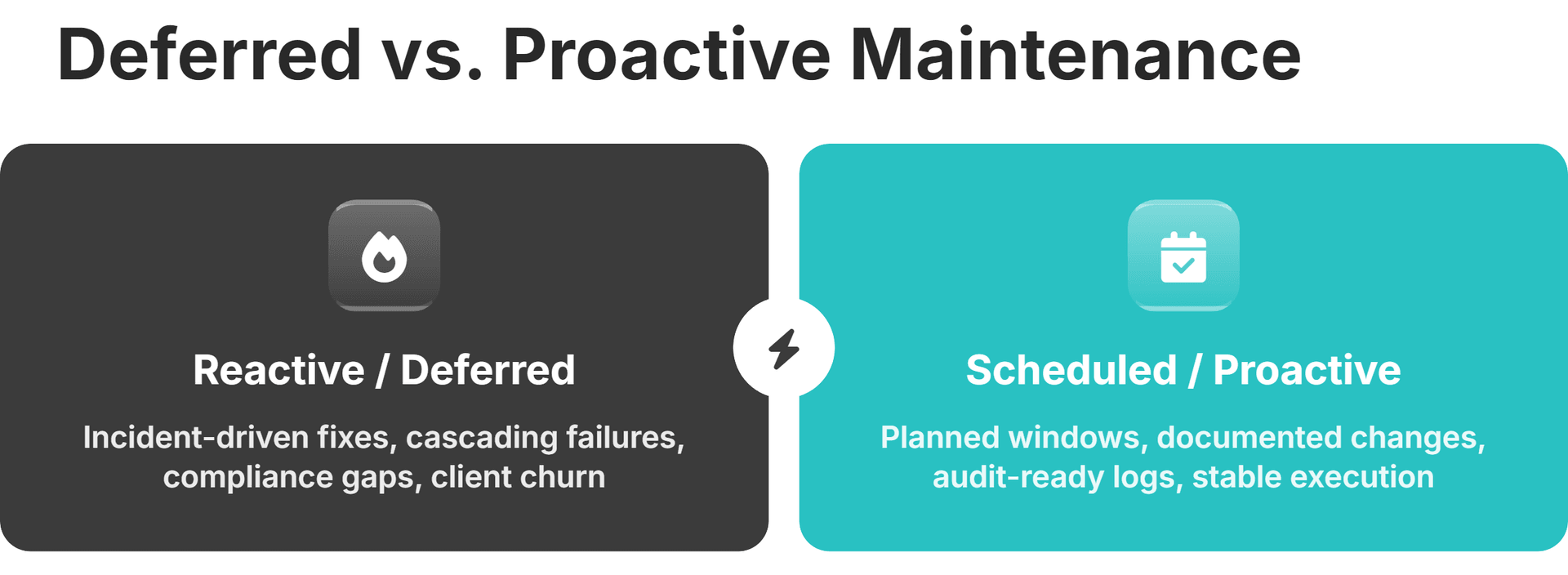
The Hidden Cost of Deferred Maintenance
Deferred maintenance compounds. A patch you skip today creates a compatibility gap next month. A configuration review you postpone lets routing inefficiencies build up across sessions. By the time someone notices, the fix that would have taken hours now takes days of troubleshooting because the problem has cascaded into dependent systems, causing breakdowns across multiple layers.
How does this show up on the business side?
Reconciliation errors accumulate silently across settlement cycles. By the time an auditor catches them, you're looking at a compliance finding that triggers a full regulatory review.
Execution quality drift is harder to spot because it happens gradually. A platform that drifts 3–5 basis points below the industry average fill rate of 97.51% generates quieter outflows as institutional desks reallocate to brokers whose numbers look better.
Scheduled maintenance windows and quarterly vendor reviews to streamline maintenance operations cost a fraction of what incident response and client remediation cost after something breaks. The gap between the two is the real price of deferral.
One metric captures this dynamic well: the maintenance ratio. That's the percentage of your maintenance activities that are planned versus reactive. A healthy platform runs mostly on scheduled work. A platform drowning in technical debt inverts that ratio, with most effort going to putting out fires. If your team spends more time reacting to incidents than preventing them, the debt is already compounding.
Protect Revenue Before Incidents Happen
B2TRADER's modular architecture separates margin, netting, and execution logic — reducing the blast radius of any individual component maintenance event.
Understanding the Four Layers of a Maintenance Framework
Effective maintenance operates across four layers. Each has its own failure modes, monitoring cadence, escalation path, and maintenance tasks tied to specific platform functions and modules. The layers are interdependent: execution health depends on liquidity integrity, back-office continuity depends on both, and security underpins everything.
Layer 1: Execution Health
Execution health is the layer your clients feel directly. Latency spikes, rejected orders, and degraded fills all register immediately on the trading desk. Without a structured checklist for this layer, these signals get buried in operational noise.
What should you track at the leadership level?
- P95/P99 order execution latency. Averages hide dangerous tail events. A platform with a 5ms average but a 200ms P99 has a problem that only shows up under load.
- Fill rate at size during volatile sessions. Normal-conditions fill rates mean little if the number drops during the sessions that matter most.
- Rejection rate and partial fill frequency by instrument and session window.
- Matching engine queue depth trends over time. A queue that grows week over week signals capacity pressure building before it becomes a visible incident.
Leadership questions to ask: What was our P99 latency during last month's highest-volume session? How does our current fill rate compare to our baseline from six months ago? When did we last run a full load test?

Layer 2: Liquidity Integrity
Liquidity degradation is the most undermonitored layer. Widening spreads and shallower book depth can persist for days before anyone flags them, because the symptoms look like normal market conditions rather than a technical problem.
The failure modes are specific. Stale pricing during high-volatility events happens when a provider's feed freezes while the market keeps moving. Provider reconnect loops fragment the order book and leave gaps in available liquidity. Spread widening that's actually a connectivity issue gets interpreted by clients as a deliberate pricing decision.
Start with spread deviation from baseline, broken down by instrument and session window. Layer in provider uptime and reconnect frequency per LP. Then measure book depth at standard size during volatile periods. Adding more liquidity providers improves resilience but also increases the maintenance surface. Each new LP relationship adds connectivity monitoring, SLA review cycles, and work orders for resolving feed issues on top of your existing load.
B2BROKER's multi-asset liquidity aggregation consolidates provider relationships into a single connectivity layer, reducing the overhead of monitoring individual LP connections across FX, crypto, indices, and commodities.
Deep, Reliable Liquidity Across 10 Major Asset Classes
FX, Crypto, Commodities, Indices & More from One Single Margin Account
Tight Spreads and Ultra-Low Latency Execution
Seamless API Integration with Your Trading Platform

Layer 3: Back-Office Continuity
Back-office failures have a longer tail than execution incidents. A matching engine stall is visible in seconds. A reconciliation break can grow for weeks before it surfaces as a regulatory finding or a billing dispute.
The first number to watch is your reconciliation break rate — and how fast those breaks close. KYC/AML exception queues matter too: an unmanaged queue grows silently until an audit exposes it. Billing accuracy by client segment, ideally tracked through a centralized maintenance management system, rounds out the picture. Measure how much lead time your team has between generating regulatory reports and the filing deadline.
Back-office systems sit at the intersection of your trading platform, your payment processor, and your compliance tooling. Every time one of those pushes an update, the integration layer needs testing. Skip that step, and CRM and back-office infrastructure quietly falls out of sync with the rest of the stack.
Layer 4: Security and Access Integrity
Security maintenance has a dual nature. It protects your operations and it satisfies regulatory documentation requirements. FCA, CySEC, and ASIC frameworks increasingly require evidence of systematic security controls, not just assurances that controls exist.
Run quarterly access control reviews covering all elevated permissions and API credentials. Measure your team's patch-to-deploy time for critical releases. If that number is drifting, the gap is a regulatory finding waiting to happen. Conduct an annual in-person penetration test with documented findings and a remediation plan signed off by leadership. Test your incident response plan with a live drill at least once a year.
Regulators care about the documentation as much as the controls. A log of patch deployments, access reviews, and test results often carries more weight during an audit than the controls themselves.
Regulatory Evidence Is a Maintenance Output
B2BROKER's infrastructure includes documented update pipelines, security protocols, and support cadence that give regulators the evidence trail they expect.
Scheduled vs. Unscheduled Maintenance
The ratio of planned to reactive maintenance is one of the clearest health indicators for any trading platform. If your team spends most of its time responding to incidents, technical debt is accumulating faster than it's being paid down.
What does good scheduled maintenance look like?
Run maintenance windows during the lowest-volume sessions and notify clients ahead of time. Complete change management documentation using a standardized template before deploying any change. Test rollback plans before go-live, and monitor the system for 48–72 hours afterward with defined escalation criteria. Every change gets logged with who approved it, what testing preceded it, and what the rollback procedure was. That log serves double duty: operational best practice and regulatory evidence.
What should a reactive response look like when incidents do happen?
A clear escalation path from detection to the decision-maker, with time SLAs at each step. Institutional clients expect a status update within 15 minutes of a confirmed incident. After resolution, complete a root cause analysis within a defined window and feed the findings back into the scheduled maintenance roadmap. An incident without a prevention commitment is an incident that will repeat. Continuous improvement depends on closing this loop.
How Maintenance Requirements Evolve Across the Brokerage Lifecycle
What counts as adequate maintenance at launch becomes insufficient as you scale. This section helps you identify where your brokerage sits today and what to prioritize next.
Early Stage: Establishing Baselines Before Debt Accumulates
Configure monitoring dashboards and set up change management documentation before you need them urgently. Run initial load simulations before client traffic scales and build maintenance into your onboarding process. The most common early-stage mistake is treating maintenance as something to add later. By the time founders circle back, the technical debt has already compounded and remediation costs significantly more.
Launching on a white-label platform with built-in monitoring gives you institutional-grade maintenance infrastructure from day one instead of retrofitting it after your first incident.
Growth Stage: Scaling Monitoring Without Scaling Overhead
As you add instruments and liquidity providers, the maintenance surface area grows with them. Dashboards that covered five instruments at launch don't automatically cover fifteen. Manual reconciliation that worked at 500 clients breaks at 5,000.
Add monitoring coverage for every new asset class and LP connection. Test cross-system integrations whenever a new component enters the stack. At this stage, a founder can no longer personally track maintenance health. The governance model needs documented ownership and delegation to maintain operational efficiency while retaining leadership-level visibility into all four layers.
Institutional Scale: Formalizing Governance and Vendor Accountability
At the institutional scale, maintenance becomes a documented program with defined KPIs reported to leadership. Formalize vendor SLA reviews on a quarterly cadence and conduct annual business continuity tests with measured recovery time objectives.
Institutional clients and regulators both expect evidence of a maintenance program. Showing that the platform works today is not enough. They want proof that you have a system for keeping it that way. At this scale, the cost of in-house maintenance staffing and 24/7 coverage often exceeds the cost of an integrated partner relationship that includes those capabilities.

Maintenance as a Regulatory Obligation
Regulators do not care whether a system failure was caused by a bug or by a skipped update. The FCA's operational resilience framework required firms to operate important business services within defined impact tolerances by 31 March 2025.
Starting 18 March 2027, new incident reporting rules (PS26/2) will require all FCA-regulated firms to report operational incidents within 24 hours of determining that a severity threshold has been met, using a standardized reporting portal shared with the PRA and Bank of England.
CySEC and ASIC frameworks carry parallel obligations on change management documentation, system integrity evidence, and business continuity testing.
Three areas surface most often in audits:
- Change management logs. Every system change needs a record of who approved it and what testing preceded deployment.
- System integrity evidence. Audit trails showing platform behavior was consistent and controls stayed active during the review period.
- Business continuity documentation. Evidence that failover has been tested and recovery time objectives have been measured.
The difference between a minor regulatory finding and a material one often comes down to whether the documentation exists. Treat regulatory maintenance as a parallel workstream to your operational maintenance: same activities, different output.

B2CORE is the ultimate forex CRM system, combining trader account management, compliance, and automation to help brokers scale and optimise operations.
14.05.25
Maintenance as Competitive Advantage
Consistent fill quality builds institutional client trust, which brings more flow, which funds better infrastructure. That cycle compounds quarter over quarter. Brokers who maintain their platforms systematically widen the gap against those who don't.
Three specific advantages accrue here. Brokers who regularly benchmark fill quality against the industry catch performance gaps before clients do. Staying current on platform versions gives you access to routing improvements and new asset class support as they ship. And institutional clients increasingly ask for documented uptime history before committing significant flow. A neglected platform cannot produce that record retroactively when a prospect requests it.
The Maintenance Governance Model
Maintenance without assigned ownership is maintenance that doesn't happen. You don't need to understand every technical detail, but you do need to ask the right questions on a consistent schedule, invest in employee training and continuous learning, verify that your maintenance staff has the right competencies, and hold your vendors accountable for documented answers.
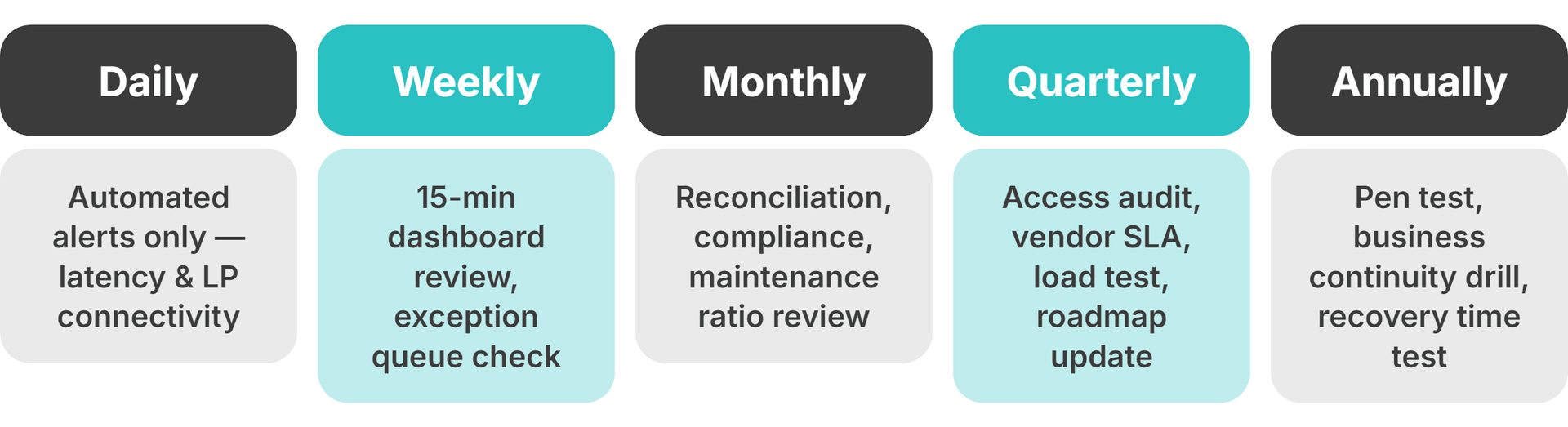
A practical cadence for founders:
- Daily: Automated alerts only. No manual review unless a threshold fires on execution latency or provider connectivity.
- Weekly: 15-minute dashboard review of execution and liquidity health. Check the back-office exception queue and any unscheduled incidents from the prior week.
- Monthly: Reconciliation accuracy and compliance reporting review. Maintenance ratio check (scheduled vs. reactive). Patch deployment SLA review. Postmortem review of any client-facing incidents that month.
- Quarterly: Access control audit and vendor SLA performance review against contractual commitments. Load testing against the current peak volume. Update the maintenance roadmap for the next quarter.
- Annually: Full penetration test with documented remediation plan. Business continuity test with measured recovery time.
How should you handle vendor accountability? Your partners should produce patch deployment logs and execution quality trend data on request. Verbal assurance is not evidence. If a vendor cannot provide documented proof when you ask, that gap is itself a maintenance finding.
Defining Escalation Triggers Before Incidents Occur
Escalation decisions made under pressure are slow and inconsistent. Define your triggers before anything breaks.
Two failure modes to avoid. Under-escalation means your team keeps trying to fix something internally past the point where a partner could have resolved it faster. Over-escalation means treating routine maintenance events as emergencies, which trains everyone to ignore the alerts.
When to escalate to your infrastructure partner immediately:
- Execution latency exceeding critical thresholds during a live session
- LP connectivity drops affecting more than one instrument class at once
- Reconciliation breaks persisting beyond your standard resolution window
- Any security incident involving unauthorized access or anomalous API activity
- A regulatory inquiry touching system behavior or audit trail integrity
When to resolve internally first: single-instrument pricing anomalies within normal volatility, routine configuration changes within pre-approved scope, and individual client reconciliation exceptions that don't reflect a systemic pattern.
Define who contacts the partner, through what channel, and what information they include. Set a response time SLA and hold the partner to it.

Explore our guide to institutional trading platforms—actionable insights for brokers and exchanges to scale, diversify, and future-proof trading operations.
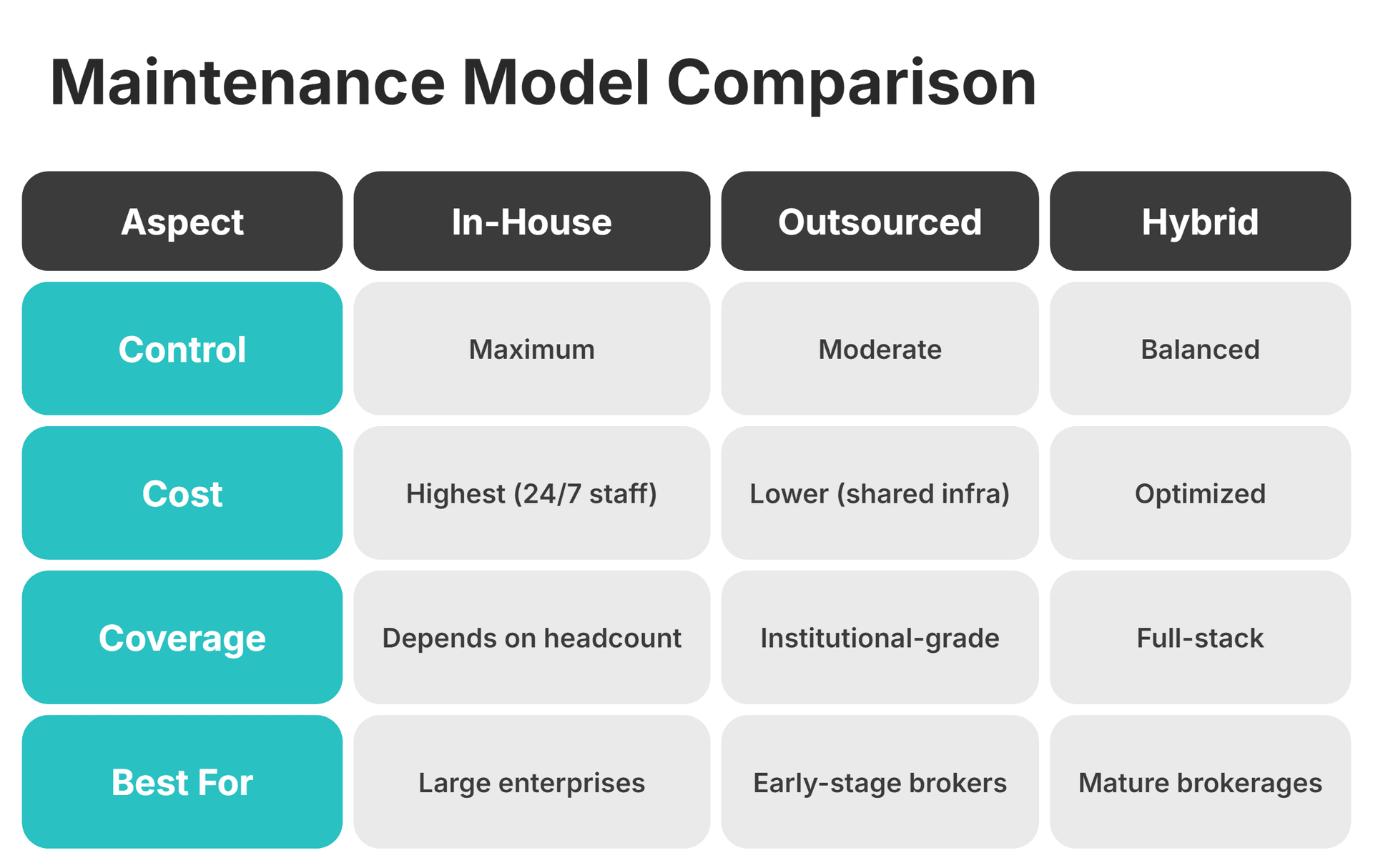
In-House vs. Outsourced Maintenance: How to Evaluate the Right Model
Most founders face a genuine decision about whether to build internal maintenance capability, outsource it, or operate a hybrid. The decision comes down to cost, coverage depth, response time, and the skill levels available within your maintenance teams at your current stage.
In-house gives you maximum control. It also requires dedicated staffing, 24/7 coverage, and continuous investment in tooling. Most early-stage brokers underestimate what that actually costs once you factor in hiring, on-call rotations, maintenance training to close the skills gap, ongoing upskilling to address evolving training needs, and the tooling budget needed to monitor all four maintenance layers.
Outsourced models through integrated infrastructure partners deliver institutional-grade monitoring and update pipelines at a fraction of the equivalent in-house cost. The trade-off is that you need strong governance to hold the partner accountable for outcomes, not just activities.
Hybrid is where most mature brokerages land. Your internal team owns governance and escalation decisions. The partner provides infrastructure, monitoring, first-line support, and hands-on training sessions for your internal staff as part of a structured training program.
A Self-Assessment Framework for Your Current Maintenance Posture
More than two or three "I don't know" answers in any single category signal that the maintenance posture in that area is reactive rather than proactive.
Execution Health
- Can you produce a P99 latency trend report for the last 90 days without asking your engineering team?
- Do you know your fill rate at size during the last high-volatility session?
- When did you last run a load test simulating 3x current peak volume?
Liquidity Integrity
- Do you have a real-time view of provider connectivity status across all LPs?
- Can you identify which provider had the most reconnect events last month?
- When did you last review spread performance against your go-live baseline?
Back-Office Continuity
- What is your current reconciliation break rate and how has it trended over the past quarter?
- When did you last audit your KYC exception queue?
- Have you run an end-to-end test of your regulatory reporting pipeline within the last 90 days?
Security and Access
- When was your access control list last reviewed and how many former staff still have active credentials?
- What is your current SLA for deploying critical security patches and are you meeting it?
- When did you last test your incident response plan with a live drill?
Common Maintenance Mistakes Brokerage Leaders Make
Treating maintenance as a technical responsibility only. When founders delegate entirely to maintenance technicians without retaining governance, accountability gaps appear across all four layers simultaneously.
Confusing monitoring with maintenance. Dashboards show you what is happening. Maintenance is the structured set of actions that determines what happens. Having dashboards is not a maintenance program.
Deferring documentation. Change logs, access reviews, and incident reports that are not created in real time cannot be reconstructed accurately later. Regulators know this.
Adding asset classes without expanding maintenance coverage. Each new instrument class or liquidity provider adds to the maintenance surface area. Many brokers expand product offerings without expanding the scope of maintenance work, monitoring, or review cadences to match.
Evaluating vendors on features, not maintenance capability. A vendor who cannot produce SLA performance data, patch deployment logs, or access control records on request is a maintenance liability regardless of platform feature quality.
Waiting for incidents to define escalation paths. Protocols designed under pressure are slower and less effective than those defined and tested in advance.
Metrics That Prove Maintenance ROI to Leadership and the Board
Maintenance programs need to demonstrate value in metrics that resonate at the board level.
Four ROI metrics resonate at the board level.
Execution cost savings: compare average fill quality before and after effective maintenance optimization, then calculate the basis-point improvement multiplied by monthly volume.
Revenue protected from downtime prevention: calculate average revenue per peak trading hour multiplied by unplanned downtime hours avoided.
Compliance cost avoidance: estimate the cost of a regulatory finding (fines, remediation, legal fees, management time) and document how maintenance reduced finding frequency.
Client retention improvement: track LTV and churn rate before and after maintenance program implementation for institutional and high-value retail segments.
The baseline requirement is non-negotiable. ROI can only be demonstrated if baselines are established before the maintenance program goes live. Retroactive baseline construction is less credible and harder to defend at the board level.
Preparing for Platform Migration Without Losing Maintenance Continuity
Migrations to a white-label trading platform or a consolidated integrated stack are high-risk maintenance events. All four layers are simultaneously disrupted, and coverage gaps during migration are when the most costly incidents occur.
What does migration maintenance require? Parallel monitoring of both legacy and new systems during the transition. A documented baseline state of all four layers on the legacy system before migration begins, so the new system has a defined target before cutover. Tested escalation paths and communication protocols on the new system before live traffic moves over. Explicit go/no-go criteria for each milestone, including maintenance readiness checks alongside functional testing.
A migration without a tested rollback plan is just a cutover with no recovery option. Institutional clients with SLA expectations need advance notice, defined maintenance windows, and a named escalation contact during the migration period.
Next Steps in Building Your Maintenance Program with B2BROKER
The framework in this guide applies regardless of your platform or vendor stack. The difference is how fast you can implement it and how deep your coverage goes from day one.
B2BROKER has spent over 10 years building infrastructure that brokerages run on, with 10+ regulatory licenses and a team supporting over 1,000 corporate clients worldwide.
When you work with B2BROKER, maintenance responsibilities are shared. You keep governance and accountability, and we deliver the liquidity aggregation, matching engine, CRM, and 24/7 support capacity that make the governance model actually executable.
Migrate Without Losing Maintenance Coverage
B2BROKER's turnkey migration support includes parallel system monitoring, technical documentation, and 24/7 support during cutover windows.
Frequently Asked Questions about Trading Platform Maintenance
- How often should a brokerage conduct a full platform maintenance review?
Quarterly at minimum, covering execution health, reconciliation accuracy, security controls, and vendor SLA performance. Monthly check-ins on execution and liquidity metrics fill the gaps between full reviews and keep the maintenance schedule on track. Vendors should also provide training resources for your team.
- What is the difference between platform maintenance and platform monitoring?
Monitoring observes the current platform state through dashboards and alerts. Maintenance is the structured set of maintenance tasks and actions that preserve and improve performance over time: updates, audits, configuration reviews, and incident remediation.
- How do you maintain platform performance during high-volatility market events?
Performance during volatility depends on preparation: stress-tested infrastructure, pre-configured failovers, and documented escalation paths defined before the event. Post-event reviews then feed real-world data back into the next maintenance cycle.
- What documentation should brokers maintain for regulatory purposes?
At minimum: change management logs with approval records, system integrity reports, business continuity test results with recovery time data, and security records covering patch history and access reviews. Regulators treat documentation gaps as evidence of control failures.
- How do you know when your current brokerage platform infrastructure has hit its maintenance ceiling?
Key signals include P95/P99 latency degradation during peak sessions, growing order management queue depth, and manual workarounds replacing previously automated back-office workflows. If these are present, the bottleneck already exists. The only question is when it surfaces at scale.






